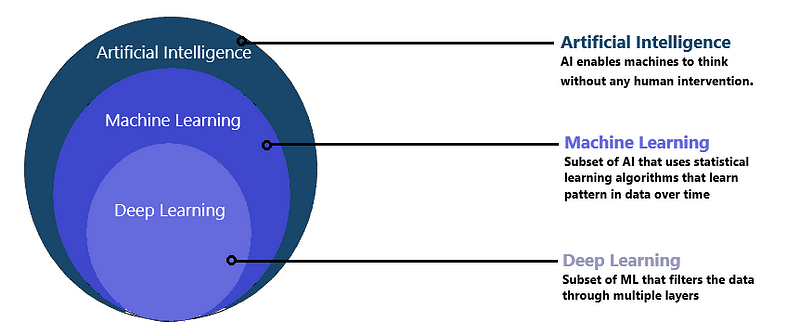
L’intelligence artificielle “Artificial Intelligence” : est un exercice purement mathématique et scientifique, mais lorsqu’elle devient informatique, elle commence à résoudre des problèmes humains.
L’apprentissage automatique “Machine Learning” : est un sous-ensemble de l’intelligence artificielle. L’apprentissage automatique est l’étude des algorithmes informatiques qui s’améliorent automatiquement grâce à l’expérience.
L’apprentissage automatique explore l’étude et la construction d’algorithmes capables d’apprendre à partir de données et de faire des prédictions à partir de données. Sur la base d’un plus grand nombre de données, l’apprentissage automatique peut modifier les actions et les réponses, ce qui le rendra plus efficace, adaptable et évolutif.

L’apprentissage profond “Deep Learning”: est une technique permettant de mettre en œuvre des algorithmes d’apprentissage automatique. Il utilise des réseaux neuronaux artificiels pour les données d’entraînement afin d’obtenir une prise de décision très prometteuse. Le réseau neuronal effectue des microcalculs avec des calculs sur de nombreuses couches et peut gérer des tâches comme les humains.
Types d’apprentissage automatique
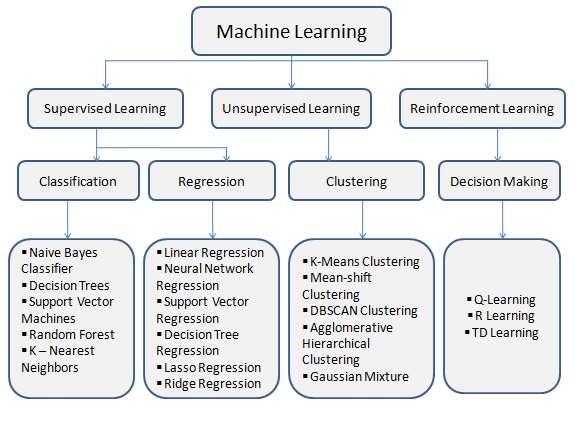
1. Apprentissage supervisé :
Dans un modèle d’apprentissage supervisé, l’algorithme apprend sur un ensemble de données étiquetées, afin de générer des prédictions attendues pour la réponse à de nouvelles données.
L’apprentissage supervisé est de deux types :
a) Classification : Dans la classification, un programme informatique est formé sur un ensemble de données d’apprentissage et, sur la base de cette formation, il classe les données dans différentes catégories. Cet algorithme est utilisé pour prédire les valeurs discrètes telles que homme|femme, vrai|faux, spam|pas spam, etc.
Types d’algorithmes de classification :
- Classificateur Naive Bayes
- Arbres de décision
- Régression logistique
- Voisins les plus proches
- Machine à vecteur de support
- Forêt aléatoire
b) Régression : La tâche de l’algorithme de régression est de trouver la fonction de mise en correspondance pour faire correspondre les variables d’entrée (x) à la variable de sortie continue (y). Les algorithmes de régression sont utilisés pour prédire des valeurs continues telles que le prix, le salaire, l’âge, les notes, etc.
Exemple :
Par exemple : prévisions météorologiques, prévisions des prix de l’immobilier, détection des fausses nouvelles, etc.
Types d’algorithmes de régression :
- Régression linéaire simple
- Régression linéaire multiple
- Régression polynomiale
- Régression par arbre de décision Régression
- Forêt aléatoire Régression
- Méthode d’ensemble
2. Apprentissage non supervisé :
Dans un modèle d’apprentissage non supervisé, l’algorithme apprend sur un ensemble de données non étiquetées et tente d’en extraire les caractéristiques, les cooccurrences et les modèles sous-jacents.
Exemple :
Par exemple, la détection des anomalies, y compris la détection des fraudes. Un autre exemple est l’ouverture d’hôpitaux d’urgence dans les zones les plus exposées aux accidents. Le regroupement K-Means permet de regrouper les zones les plus exposées en grappes et de définir un centre de grappe (c’est-à-dire un hôpital) pour chaque grappe (c’est-à-dire les zones exposées aux accidents).
Types d’apprentissage non supervisé :
- Regroupement
- Détection d’anomalies
- Association
- Autoencodeurs
- Modèles de variables latentes
- Réseaux neuronaux
3. Apprentissage par renforcement :
L’apprentissage par renforcement est un type d’apprentissage automatique dans lequel le modèle apprend à se comporter dans un environnement en effectuant certaines actions et en analysant les réactions.
L’apprentissage par renforcement prend les mesures appropriées afin de maximiser la réponse positive dans une situation donnée. Le modèle de renforcement décide des actions à entreprendre pour réaliser une tâche donnée, c’est pourquoi il est tenu d’apprendre de l’expérience elle-même.
Exemple :
Prenons l’exemple d’un bébé qui apprend à marcher. Dans le premier cas, lorsque le bébé commence à marcher et qu’il atteint le chocolat, puisque le chocolat est l’objectif final pour le bébé, la réaction du bébé est positive car il est heureux. Dans le second cas, lorsque le bébé commence à marcher et qu’en marchant, il est frappé par la chaise et ne peut atteindre le chocolat, il se met à pleurer, ce qui est une réaction négative. Il s’agit de dire comment nous, les humains, apprenons par essais et erreurs. Ici, le bébé est « l’agent », le chocolat est la « récompense » et il y a de nombreux obstacles entre les deux. L’agent essaie maintenant plusieurs façons et trouve le meilleur chemin possible pour atteindre la récompense.
Cycle de vie de l’apprentissage automatique :
L’apprentissage automatique permet d’accroître les performances et la productivité des tâches. Il comprend l’apprentissage et l’autocorrection lorsqu’il est confronté à de nouvelles données.
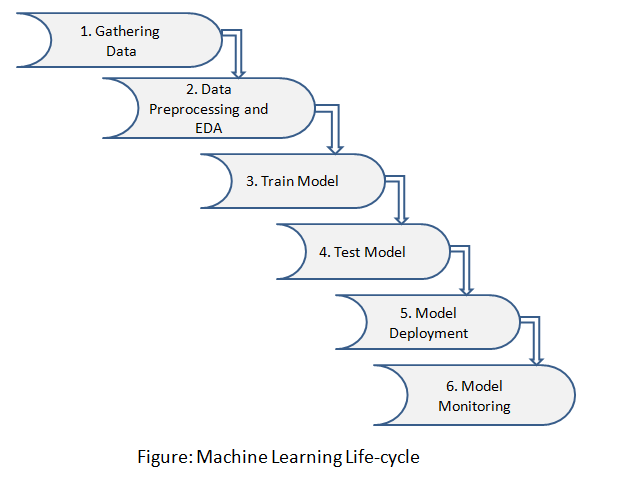
Le cycle de vie de l’apprentissage automatique comprend six étapes principales :
Étape 1 : Collecte des données
Identifier diverses sources de données telles que Kaggle et collecter l’ensemble de données requis
Étape
2 : Prétraitement des données et AED
Au cours de cette étape, nous analysons les données pour détecter les valeurs manquantes, les données dupliquées et les données invalides à l’aide de différentes techniques analytiques. Les données sont également prétraitées pour l’extraction des caractéristiques, l’analyse des caractéristiques et la visualisation des données.
Étape 3 : Formation du modèle
Nous utilisons un ensemble de données pour former le modèle à l’aide de divers algorithmes d’apprentissage automatique. Il est important d’entraîner un modèle pour qu’il puisse comprendre les différents modèles, règles et caractéristiques.
Étape 4 : Test du modèle
Dans cette étape, nous vérifions la précision de notre modèle en fournissant un ensemble de données de test au modèle formé.
Étape 5 : Déploiement du modèle
Le déploiement du modèle consiste à intégrer un modèle d’apprentissage automatique dans un environnement de production existant qui reçoit des données d’entrée et renvoie des données de sortie pour prendre des décisions commerciales basées sur des données. Les différentes technologies que vous pouvez utiliser pour déployer vos modèles d’apprentissage automatique sont répertoriées :
- Docker
- Kubernetes
- AWS SageMaker
- MLFlow
- Azure Machine Learning Service
Étape 6 : Surveillance du modèle
Après le déploiement du modèle, vient la surveillance du modèle qui contrôle vos modèles d’apprentissage automatique pour des facteurs tels que les erreurs, les pannes et la latence et, plus important encore, pour s’assurer que votre modèle conserve les performances souhaitées.
La surveillance du modèle est très importante car vos modèles se dégradent au fil du temps en raison de plusieurs facteurs tels que les données non vues, les changements dans l’environnement et les relations entre les variables.
Quelques applications de l’apprentissage automatique dans le monde réel :
- Traduction automatique des langues dans Google Translate
- Sélection plus rapide des itinéraires dans Google Map
- Voiture sans conducteur/autonome
- Smartphone avec reconnaissance faciale
- Reconnaissance vocale
- Système de recommandation de publicités
- Système de recommandation de Netflix
- Suggestion de marquage automatique d’amis dans Facebook
- Négociation boursière
- Détection de fraude
- Prévision météorologique
- Diagnostic médical
- Chatbot
- Apprentissage automatique dans le domaine de l’agriculture
Avantagesde l’apprentissage automatique :
- Automatisation du travail
- Capacité prédictive puissante
- Augmentation des ventes sur le marché du commerce électronique
- Avantages de l’apprentissage automatique dans le domaine médical pour améliorer le diagnostic médical, le développement de médicaments
- L’apprentissage
- automatiqueest utilisé dans la chirurgie médicale robotique
- L’apprentissage automatique dans le domaine financier augmente la productivité, accroît les revenus et sécurise les transactions
- Modélisation des données pour prendre des décisions utiles
Conclusion :
L’apprentissage automatique peut être utilisé dans presque tous les secteurs de la vie humaine pour rendre notre travail efficace, robuste et simple. Comme nous le savons, chaque chose a ses avantages et ses inconvénients, l’apprentissage automatique a également ses désavantages, par exemple, avec l’augmentation de l’apprentissage automatique, de nombreuses personnes peuvent perdre leur emploi actuel. Mais le plus important est qu’il est bénéfique à long terme pour l’humanité.
👉🏼 Lecture complémentaire :
- Suno AI : tout ce qu’il faut savoir
- Comment apprendre l’Intelligence Artificielle à partir de zéro en 2026 : guide complet par des experts
- Comment le jeu vidéo stimule l’innovation dans l’IA et la technologie graphique
- 7 conseils pour tirer le meilleur parti de Nano Banana Pro
- Comment éviter les dérives : comprendre les enjeux éthiques de l’IA aujourd’hui










{kind=link}