Les voitures autonomes et les robots de Google font couler beaucoup d’encre, mais le véritable avenir de l’entreprise réside dans l’apprentissage automatique, la technologie qui permet aux ordinateurs de devenir plus intelligents et plus personnels.
Nous vivons probablement la période la plus déterminante de l’histoire de l’humanité. C’est la période où l’informatique est passée des gros ordinateurs centraux aux PC et à l’informatique en nuage. Mais ce qui est déterminant, ce n’est pas ce qui s’est passé, mais ce qui nous attend dans les années à venir.

Ce qui rend cette période excitante et passionnante pour des personnes comme nous, c’est la démocratisation des différents outils, techniques et algorithmes d’apprentissage automatique qui ont suivi l’essor de l’informatique. Bienvenue dans le monde de la science des données !
Aujourd’hui, en tant que data scientist, je peux construire des machines qui traitent des données avec des algorithmes complexes pour quelques dollars de l’heure. Mais il n’a pas été facile d’en arriver là ! J’ai connu des jours et des nuits sombres.
Cet article traite de quelques algorithmes populaires d’apprentissage automatique. Nous discuterons des différents types d’algorithmes d’apprentissage automatique et éluciderons les catégories, telles que l’apprentissage supervisé et non supervisé. Vous apprendrez également comment utiliser ces algorithmes d’apprentissage automatique. À la fin de cet article, vous serez en mesure de sélectionner les algorithmes appropriés pour vos tâches.
Qui peut bénéficier le plus de ce guide ?
Ce que je propose aujourd’hui est probablement le guide le plus précieux que j’ai jamais créé. L’idée derrière la création de ce guide est de simplifier le parcours des scientifiques de données en herbe et des enthousiastes de l’apprentissage automatique (qui fait partie de l’intelligence artificielle) à travers le monde. Ce guide vous permettra de travailler sur des problèmes d’apprentissage automatique et d’acquérir de l’expérience. Je vous propose une compréhension de haut niveau de divers algorithmes d’apprentissage automatique ainsi que des codes R et Python pour les exécuter. Cela devrait suffire à vous mettre les mains dans le cambouis. Vous pouvez également consulter notre cours sur l’apprentissage automatique.
Principes essentiels des algorithmes d’apprentissage automatique avec implémentation en R et Python. J’ai délibérément omis les statistiques qui sous-tendent ces techniques et les réseaux neuronaux artificiels, car vous n’avez pas besoin de les comprendre au départ. Donc, si vous cherchez une compréhension statistique de ces algorithmes, vous devriez regarder ailleurs.
Mais si vous voulez vous équiper pour commencer à construire un projet d’apprentissage automatique, vous allez être comblé, surtout lorsqu’il s’agit de développement de logiciels pour les environnements de démarrage.
3 Types d’algorithmes
Algorithmes d’apprentissage supervisé :
Ces algorithmes consistent en une variable cible/de résultat (ou variable dépendante) qui doit être prédite à partir d’un ensemble donné de prédicteurs (variables indépendantes). Les algorithmes d’apprentissage supervisé pour la classification et la régression impliquent la génération d’une fonction qui associe les données d’entrée aux résultats souhaités. À l’aide de cet ensemble de variables, nous générons une fonction qui associe les données d’entrée aux sorties souhaitées. Le processus d’apprentissage se poursuit jusqu’à ce que le modèle atteigne le niveau de précision souhaité sur les données d’apprentissage.
Les meilleurs algorithmes d’apprentissage automatique supervisé comprennent la régression, l’arbre de décision, la forêt aléatoire, le KNN, la régression logistique, etc. Chacun de ces algorithmes répond à différents types de données et de problèmes, ce qui les rend largement applicables dans divers domaines.
Algorithmes d’apprentissage non supervisé :
Ces algorithmes travaillent avec des données non étiquetées, où il n’y a pas de variable cible/résultat à prédire. Les algorithmes d’apprentissage non supervisé pour le regroupement et l’exploration de données sont conçus pour identifier des modèles ou des structures cachés dans les données.
À l’aide de ces modèles, nous regroupons les points de données présentant des caractéristiques similaires, en générant une fonction qui associe les données d’entrée à des grappes ou à des groupes. Ce processus se poursuit jusqu’à ce que le modèle parvienne à identifier des schémas significatifs dans les données.
Les algorithmes d’apprentissage non supervisé les plus courants sont le regroupement K-Means, le regroupement hiérarchique et l’analyse en composantes principales (ACP). Chacun de ces algorithmes répond à différents types de données et de problèmes, ce qui les rend largement applicables dans divers domaines tels que la segmentation de la clientèle, la détection des anomalies et la reconnaissance des formes.
Algorithmes d’apprentissage par renforcement
Comment cela fonctionne-t-il ? Cet algorithme permet d’entraîner la machine à prendre des décisions spécifiques. La machine est exposée à un environnement où elle s’entraîne continuellement par essais et erreurs. La machine apprend de ses expériences passées et tente d’acquérir les meilleures connaissances possibles pour prendre des décisions commerciales précises. Exemple d’apprentissage par renforcement : Processus de décision de Markov
👉🏼 Lecture complémentaire : Machine learning en français : Tout ce que vous devez savoir sur l’apprentissage automatique
Liste des 10 algorithmes d’apprentissage automatique les plus courants
Voici la liste des algorithmes d’apprentissage automatique les plus courants. Ces algorithmes peuvent être appliqués à presque tous les problèmes de données :
- Régression linéaire
- Régression logistique
- Arbre de décision
- SVM
- Naive Bayes
- kNN
- K-Means
- Random Forest
- Algorithmes de réduction de la dimensionnalité
- Algorithmes de boosting de gradient
- GBM
- XGBoost
- LightGBM
- CatBoost
1. Régression linéaire
Elle est utilisée pour estimer des valeurs réelles (coût des maisons, nombre d’appels, ventes totales, etc.) sur la base d’une ou de plusieurs variables continues. Dans ce cas, nous établissons la relation entre les variables indépendantes et dépendantes en ajustant la meilleure ligne.
Cette ligne de meilleur ajustement est connue sous le nom de ligne de régression et est représentée par une équation linéaire Y= a*X + b.
2. Régression logistique :
Ne vous fiez pas à son nom ! Il s’agit d’un algorithme de classification et non de régression. Il est utilisé pour estimer des valeurs discrètes (valeurs binaires telles que 0/1, oui/non, vrai/faux) sur la base d’un ensemble donné de variables indépendantes. En d’autres termes, il prédit la probabilité d’occurrence d’un événement en adaptant les données à une fonction logistique. C’est pourquoi elle est également connue sous le nom de régression logit. Puisqu’elle prédit la probabilité, ses valeurs de sortie se situent entre 0 et 1 (comme prévu).
Essayons à nouveau de comprendre cela à l’aide d’un exemple simple.
Supposons que votre ami vous donne une énigme à résoudre. Il n’y a que deux scénarios possibles : soit vous le résolvez, soit vous ne le résolvez pas. Imaginons maintenant que l’on vous propose un large éventail d’énigmes/de questionnaires afin de déterminer les matières dans lesquelles vous êtes doué(e). Le résultat de cette étude serait à peu près le suivant : si l’on vous pose un problème de trigonométrie en classe de seconde, vous avez 70 % de chances de le résoudre. En revanche, s’il s’agit d’une question d’histoire de cinquième année, la probabilité d’obtenir une réponse n’est que de 30 %. C’est ce que vous offre la régression logistique.
3. Arbre de décision :
Il s’agit de l’un de mes algorithmes préférés, que j’utilise assez fréquemment. Il s’agit d’un type d’algorithme d’apprentissage supervisé qui est principalement utilisé pour les problèmes de classification. Il est surprenant de constater qu’il fonctionne aussi bien pour les variables dépendantes catégorielles que pour les variables dépendantes continues.
Dans cet algorithme, nous divisons la population en deux ou plusieurs ensembles homogènes. Cela se fait sur la base des attributs/ variables indépendantes les plus significatifs afin de créer des groupes aussi distincts que possible. Pour plus de détails, vous pouvez lire L’arbre de décision simplifié.
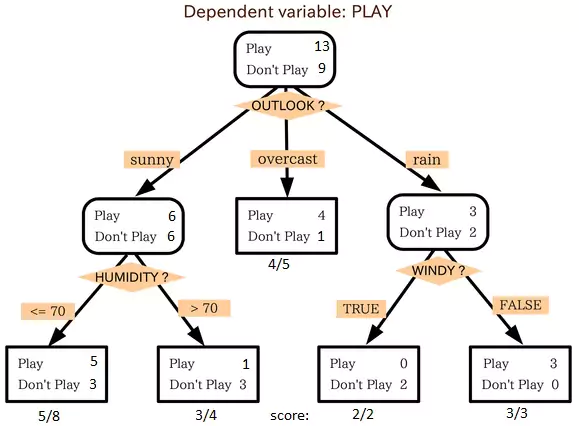
Dans l’image ci-dessus, vous pouvez voir que la population est classée en quatre groupes différents sur la base d’attributs multiples afin d’identifier « s’ils joueront ou non ». Pour diviser la population en différents groupes hétérogènes, l’arbre de décision utilise diverses techniques telles que le Gini, le gain d’information, le chi carré et l’entropie.
La meilleure façon de comprendre le fonctionnement d’un arbre de décision est de jouer à Jezzball, un jeu classique de Microsoft (image ci-dessous). Essentiellement, vous disposez d’une pièce dont les murs se déplacent et vous devez créer des murs de manière à ce que la zone maximale soit dégagée sans les balles.
Ainsi, chaque fois que vous divisez la pièce par un mur, vous essayez de créer deux populations différentes dans la même pièce. Les arbres de décision fonctionnent de manière très similaire en divisant une population en autant de groupes différents que possible.
4. SVM (Support Vector Machine)
Il s’agit d’une méthode de classification. Dans l’algorithme SVM, chaque donnée est représentée par un point dans un espace à n dimensions (où n est le nombre de caractéristiques), la valeur de chaque caractéristique étant la valeur d’une coordonnée particulière.
Par exemple, si nous ne disposons que de deux caractéristiques telles que la taille et la longueur des cheveux d’un individu, nous représenterons d’abord ces deux variables dans un espace bidimensionnel où chaque point aura deux coordonnées (ces coordonnées sont connues sous le nom de vecteurs de support).
5. Naive :
Bayes Naive Bayes est une technique de classification basée sur le théorème de Bayes avec une hypothèse d’indépendance entre les prédicteurs. En termes simples, un classificateur Naive Bayes suppose que la présence d’une caractéristique particulière dans une classe n’est pas liée à la présence de toute autre caractéristique.
Par exemple, un fruit peut être considéré comme une pomme s’il est rouge, rond et d’un diamètre d’environ 3 pouces. Même si ces caractéristiques dépendent les unes des autres, un algorithme de classification Naive Bayes traiterait chaque propriété comme contribuant indépendamment à la probabilité que ce fruit soit une pomme.
Le modèle bayésien naïf est facile à construire et particulièrement utile pour les très grands ensembles de données. Outre sa simplicité, la classification Naive Bayes est connue pour être plus performante que les méthodes les plus sophistiquées pour des tâches telles que la classification de textes, la détection de spams et l’analyse des sentiments.
6. kNN (k- Nearest Neighbors) :
Le KNN peut être utilisé pour les problèmes de classification et de régression. Cependant, il est plus largement utilisé comme algorithme de classification dans l’apprentissage automatique. K-Nearest Neighbors est un algorithme simple et intuitif qui stocke tous les cas disponibles et classe les nouveaux cas par un vote majoritaire de ses k plus proches voisins. La classe attribuée à un nouveau cas est celle qui est la plus fréquente parmi ses K plus proches voisins, mesurée par une fonction de distance.
Les fonctions de distance utilisées dans le KNN peuvent être des distances euclidiennes, de Manhattan, de Minkowski ou de Hamming. Les trois premières sont généralement utilisées pour les variables continues, tandis que la distance de Hamming s’applique aux variables catégorielles. Si K = 1, le cas est simplement assigné à la classe de son voisin le plus proche. Cependant, le choix de la bonne valeur de K peut s’avérer difficile et dépend souvent de l’ensemble de données utilisé dans la modélisation KNN.
7. K-Means :
Il s’agit d’un type d’algorithme non supervisé qui résout le problème du regroupement. Sa procédure est simple et facile à mettre en œuvre pour classer un ensemble de données donné dans un certain nombre de grappes (par exemple, k grappes). Les points de données à l’intérieur d’une grappe sont homogènes et hétérogènes par rapport aux autres groupes.
Vous vous souvenez avoir déterminé des formes à partir de taches d’encre ? La méthode des k moyennes est quelque peu similaire à cette activité. Vous observez la forme et l’étalement pour déterminer le nombre de grappes/populations différentes présentes !
8. Random
Forest Random Forest est un terme de marque déposée désignant un ensemble d’apprentissage d’arbres de décision. Dans Random Forest, nous avons une collection d’arbres de décision (également connus sous le nom de « Forest »). Pour classer un nouvel objet en fonction de ses attributs, chaque arbre donne une classification, et on dit que l’arbre « vote » pour cette classe. La forêt choisit la classification ayant le plus de votes (parmi tous les arbres de la forêt).
Chaque arbre est planté et grandit comme suit :
- Si le nombre de cas dans l’ensemble d’apprentissage est N, un échantillon de N cas est pris au hasard mais avec remplacement. Cet échantillon constituera l’ensemble d’apprentissage pour la croissance de l’arbre.
- S’il y a M variables d’entrée, un nombre m<<M est spécifié de sorte qu’à chaque nœud, m variables sont sélectionnées au hasard parmi les M, et la meilleure division sur ce m est utilisée pour diviser le nœud. La valeur de m est maintenue constante pendant la croissance de la forêt.
- Chaque arbre est cultivé dans toute la mesure du possible. Il n’y a pas d’élagage.
9. Algorithmes de réduction de la dimensionnalité
Au cours des 4 à 5 dernières années, on a assisté à une augmentation exponentielle de la capture de données à tous les stades possibles. Les entreprises, les agences gouvernementales et les organismes de recherche ne se contentent pas d’inventer de nouvelles sources, ils capturent également des données de manière très détaillée.
Par exemple, les sociétés de commerce électronique recueillent davantage de détails sur leurs clients, comme leurs données démographiques, leur historique de navigation sur le web, ce qu’ils aiment ou n’aiment pas, leur historique d’achat, leurs commentaires, et bien d’autres choses encore, afin de leur offrir une attention plus personnalisée que celle de l’épicier le plus proche de chez eux.
En tant que scientifiques des données, les données qui nous sont proposées sont également composées de nombreuses caractéristiques, ce qui semble être une bonne chose pour construire un modèle robuste, mais il y a un défi à relever. Comment identifier les variables les plus significatives parmi 1000 ou 2000 ? Dans de tels cas, l’algorithme de réduction de la dimensionnalité nous aide, ainsi que divers autres algorithmes tels que l’arbre de décision, la forêt aléatoire, l’ACP (analyse en composantes principales), l’analyse factorielle, l’identité basée sur la matrice de corrélation, le rapport des valeurs manquantes, et d’autres encore.
10. Algorithmes de renforcement du gradient :
Examinons maintenant les 4 algorithmes de renforcement du gradient les plus couramment utilisés.
GBM :
Le GBM est un algorithme de boosting utilisé lorsque nous disposons d’un grand nombre de données pour faire une prédiction avec un pouvoir de prédiction élevé. Le boosting est en fait un ensemble d’algorithmes d’apprentissage qui combine la prédiction de plusieurs estimateurs de base afin d’améliorer la robustesse par rapport à un estimateur unique. Il combine plusieurs prédicteurs faibles ou moyens pour construire un prédicteur fort. Ces algorithmes de boosting fonctionnent toujours bien dans les compétitions de science des données comme Kaggle, AV Hackathon et CrowdAnalytix.
XGBoost :
Un autre algorithme classique de gradient-boosting connu pour être le choix décisif entre la victoire et la défaite dans certaines compétitions Kaggle est le XGBoost. Il possède un pouvoir prédictif extrêmement élevé, ce qui en fait le meilleur choix pour la précision dans les événements. Il possède à la fois un modèle linéaire et un algorithme d’apprentissage par arbre, ce qui rend l’algorithme presque 10 fois plus rapide que les techniques existantes de booster de gradient.
L’un des aspects les plus intéressants de XGBoost est qu’il s’agit également d’une technique de boosting régularisée. Elle permet de réduire la modélisation par surajustement et prend en charge un grand nombre de langages tels que Scala, Java, R, Python, Julia et C++.
La prise en charge comprend diverses fonctions objectives, notamment la régression, la classification et le classement. Il prend en charge l’entraînement distribué et généralisé sur de nombreuses machines qui englobent les clusters GCE, AWS, Azure et Yarn. XGBoost peut également être intégré à Spark, Flink et d’autres systèmes de flux de données en nuage avec une validation croisée intégrée à chaque itération du processus de boosting.
LightGBM :
LightGBM est un cadre d’amélioration du gradient qui utilise des algorithmes d’apprentissage basés sur les arbres. Il est conçu pour être distribué et efficace avec les avantages suivants :
- Vitesse d’apprentissage plus rapide et plus grande efficacité
- Faible utilisation de la mémoire
- Meilleure précision
- Prise en charge de l’apprentissage parallèle et GPU
- Capacité à traiter des données à grande échelle
- Le cadre est un gradient-boosting rapide et performant basé sur des algorithmes d’arbre de décision utilisés pour le classement, la classification et de nombreuses autres tâches d’apprentissage automatique. Il a été développé dans le cadre du projet Distributed Machine Learning Toolkit de Microsoft.
Catboost :
CatBoost est l’un des algorithmes d’apprentissage machine open-source de Yandex. Il peut facilement s’intégrer à des frameworks d’apprentissage profond tels que TensorFlow de Google et Core ML d’Apple. L’avantage de CatBoost est qu’il ne nécessite pas d’entraînement intensif des données comme d’autres modèles d’apprentissage automatique et qu’il peut fonctionner sur une variété de formats de données, ce qui n’enlève rien à sa robustesse.
Catboost peut traiter automatiquement les variables catégorielles sans afficher l’erreur de conversion de type, ce qui vous permet de vous concentrer sur l’amélioration de votre modèle plutôt que sur le tri d’erreurs triviales. Assurez-vous de bien gérer les données manquantes avant de procéder à l’implémentation.
Conclusion :
À présent, je suis sûr que vous avez une idée des algorithmes d’apprentissage automatique couramment utilisés. Ma seule intention en écrivant cet article et en fournissant les codes en R et Python est de vous permettre de commencer tout de suite. Si vous souhaitez maîtriser les algorithmes d’apprentissage automatique, commencez tout de suite. Prenez des problèmes, développez une compréhension physique du processus, appliquez ces codes et amusez-vous !
J’espère que cet article vous a plu et qu’il vous a permis de mieux comprendre les algorithmes de science des données, les modèles d’apprentissage automatique et les algorithmes d’apprentissage automatique.
👉🏼 Lecture complémentaire :
- Suno AI : tout ce qu’il faut savoir
- Comment apprendre l’Intelligence Artificielle à partir de zéro en 2026 : guide complet par des experts
- Comment le jeu vidéo stimule l’innovation dans l’IA et la technologie graphique
- 7 conseils pour tirer le meilleur parti de Nano Banana Pro
- Comment éviter les dérives : comprendre les enjeux éthiques de l’IA aujourd’hui

Sylvere Gelien est un Consultant en Marketing Digital & Stratégie eCommerce chez @Search Engine Spot















{kind=link}